隨著微服務架構的普及,一個業務請求往往需要跨越多個服務節點,傳統的單體應用日志排查方式已難以應對分布式環境下的問題定位。Spring Boot 2.x 結合 Spring Cloud Sleuth 和 ELK(Elasticsearch、Logstash、Kibana)技術棧,為信息系統集成服務提供了一套高效、清晰的分布式日志管理與追蹤解決方案。本文將詳細介紹如何實現此集成,并闡述其在企業級服務集成中的關鍵價值。
一、核心組件簡介
- Spring Cloud Sleuth: 作為分布式追蹤工具,它為Spring Boot應用自動注入追蹤ID(Trace ID)和跨度ID(Span ID)。這些ID會隨著請求在服務間傳遞,從而將一次分布式請求的所有日志關聯起來,形成完整的調用鏈視圖。
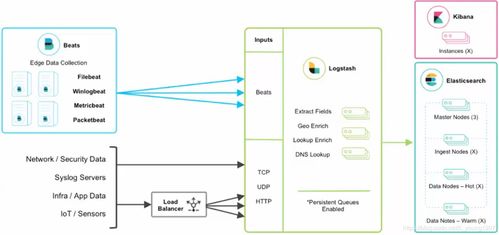
- ELK Stack:
- Elasticsearch: 一個分布式、RESTful風格的搜索和分析引擎,負責存儲和索引日志數據。
- Logstash: 一個數據處理管道,負責收集、解析、過濾和轉發日志到Elasticsearch。
- Kibana: 一個數據可視化平臺,為Elasticsearch中的數據提供豐富的圖表和儀表盤,用于日志查詢與分析。
二、集成實施步驟
步驟1:Spring Boot 應用集成 Sleuth
在需要進行日志追蹤的Spring Boot 2.x 微服務項目中,添加Sleuth依賴(通常與Zipkin依賴一同引入,但本文聚焦ELK日志管理,故不展開Zipkin)。
<!-- pom.xml -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>應用啟動后,Sleuth會自動為日志輸出添加 [application-name, traceId, spanId, exportable] 格式的追蹤信息,使得日志本身已具備鏈路標識。
步驟2:配置日志輸出格式
為了便于Logstash解析,建議將日志格式統一為JSON。以Logback為例,在 logback-spring.xml 配置文件中,使用如 logstash-logback-encoder 依賴和配置。
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>6.6</version>
</dependency>配置一個輸出為JSON格式的Appender,確保 traceId 和 spanId 作為獨立字段輸出。
步驟3:部署與配置ELK Stack
- 部署Elasticsearch與Kibana: 可通過Docker容器快速部署,確保網絡互通。
- 配置Logstash: 創建Logstash配置文件(如
logstash.conf),定義輸入(從應用收集日志,如通過TCP/UDP端口或文件)、過濾(解析JSON,可增強字段)和輸出(到Elasticsearch)。關鍵是在過濾階段,確保能正確解析Sleuth注入的追蹤字段。 - 應用日志指向Logstash: 配置Spring Boot應用的日志Appender,將JSON格式的日志通過網絡發送到Logstash監聽的端口。
步驟4:在Kibana中可視化與查詢
- 在Kibana中創建索引模式(如
logstash-*),關聯Elasticsearch中存儲的日志索引。 - 在 Discover 頁面,即可查詢日志。通過
traceId字段進行精確搜索,可以一次性拉出與該次請求相關的、跨所有服務的全部日志條目,實現端到端的請求追蹤。 - 可以利用
traceId或application-name等字段創建可視化圖表和儀表盤,監控服務調用鏈路健康狀況。
三、在信息系統集成服務中的價值體現
在復雜的企業信息系統集成場景中,該方案提供了以下核心優勢:
- 快速故障定位: 當集成流程在多個系統間出現錯誤時,運維人員只需獲取一個
traceId,即可在Kibana中全景式地還原請求的完整路徑和狀態,精準定位故障服務及具體代碼位置,極大縮短MTTR(平均修復時間)。 - 性能分析與優化: 通過分析調用鏈中各Span的耗時,可以直觀識別出性能瓶頸所在的服務或接口,為系統優化提供數據支撐。
- 提升運維可視化: 統一的日志管理平臺打破了服務間的日志孤島,提供了全局的、可搜索的運維視圖,降低了系統復雜性帶來的運維難度。
- 增強審計與合規性: 完整的調用鏈日志為業務操作追溯、安全審計和合規性檢查提供了不可篡改的數據記錄。
四、注意事項與最佳實踐
- 日志采樣: 在高并發場景下,全量采集日志可能帶來性能與存儲壓力。可配置Sleuth的采樣率,或僅對錯誤請求進行詳細追蹤。
- 字段標準化: 在Logstash過濾器中,建議對關鍵字段(如日志級別、服務名、追蹤ID)進行標準化處理,便于統一分析。
- 索引生命周期管理: 在Elasticsearch中為日志索引設置合理的生命周期策略(ILM),如按時間滾動、自動刪除過期數據,以控制存儲成本。
- 安全與權限: 確保ELK集群的訪問安全,并在Kibana中根據團隊角色配置不同的數據訪問權限。
###
將Spring Boot 2.x、Spring Cloud Sleuth與ELK棧相結合,構建的分布式日志追蹤系統,是現代微服務架構和復雜信息系統集成項目中不可或缺的運維基礎組件。它不僅是解決問題的工具,更是提升系統可觀測性、保障服務穩定性和交付質量的關鍵工程實踐。通過實施此方案,技術團隊能夠獲得強大的洞察力,從而更自信地管理日益復雜的分布式集成環境。